
springBoot
简介
Spring Boot是一种简化 Spring应用开发的框架,提供了快速构建生产级应用的能力。通过Spring Boot,我们可以轻松地初始化项目,配置依赖,开发RESTful接口,并部署到生产环境
什么是Spring Boot?
Spring Boot是基于Spring的开发框架,提供了一系列开箱即用的功能,包括:
- 自动化配置(Auto Configuration)
- 内嵌服务器(Embedded Server,如Tomcat)
- 配置文件管理(application.properties或application.yml)
- 健康检查、监控和管理(Actuator)
配置
配置pom
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.4</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>配置启动器
@SpringBootApplication
public class BootApp {
public static void main(String[] args) {
SpringApplication.run(BootApp.class, args);
}
}编写controller
package com.origin.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/hello")
public class HelloController {
@GetMapping("/f1")
public String f1(){
return "Hello f1";
}
@PostMapping("/f2")
public String f2(){
return "Hello f2";
}
}这样一个默认配置的springboot项目就构建好了,若要自定义配置则需配置yml文件
配置yml文件
server:
port: 8001
spring:
application:
name: boot01接收前端参数
@GetMapping("/f1")
public String f1(@RequestParam int x,@RequestParam String line) {
return "Hello_f1_"+(++x)+"_"+line;
}定义返回值类
1、每个方法定义一个返回值类—繁琐,杂乱
@GetMapping("/f1")
public F1Response f1(@RequestParam int x, @RequestParam String line) {
F1Response f1Response = new F1Response();
f1Response.setId(1);
f1Response.setName("分组1");
List<F1Response.Item> items = new ArrayList<>();
items.add(new F1Response.Item(101,"落霞与孤鹜齐飞"));
items.add(new F1Response.Item(102,"秋水共长天一色"));
f1Response.setItemList(items);
return f1Response;
}2、全局统一返回值
@Data
@AllArgsConstructor
@NoArgsConstructor
public class R {
private int code;
private String msg;
private Object data;
public static R ok(Object data) {
R r = new R();
r.setCode(200);
r.setMsg("success");
return r;
}
private static R fail(Object data) {
R r = new R();
r.setCode(500);
r.setMsg("fail");
return r;
}
}
注解
最常用
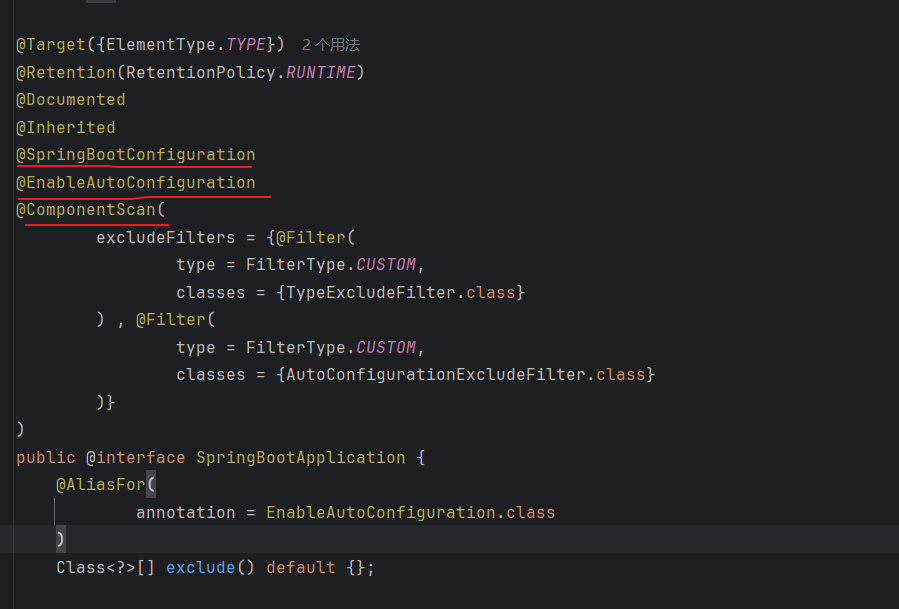
@SpringBootApplication
@SpringBootApplication
public class BootApp {
public static void main(String[] args) {
SpringApplication.run(BootApp.class, args);
}
}
@Controller
@ResponseBody
返回值,被转化为json格式
@RestController
@Controller 和 ResponseBody 的融合注解
@RequestMapper
定义请求的路径
@XXMapping
@GetMapping
@GetMapping(“/f1”)相当于@RequestMapping(value = “/f1”, method = RequestMethod.GET)
@PutMapping
@DeleteMapping
@PostMapping
…
@Autowired
@Autowired
HelloServiceImpl helloService;@Component
@Service
@Configuration
@Configuration
public class AppConfig {
@Bean(name = "bbb")
public B bb(){
B b = new B();
b.setBName("zhangsan");
return b;
}
@Bean(name = "aaa")
public A aa(){
A a = new A();
a.setAName("lisi");
a.setB(bb()); //ref
return a;
}
}@ComponentScan
@Repository
jpa中标记Repository类的注解,标注访问层的类(Dao层)
@Mapper
mybatis的注解
@RequestBody
用于将请求体中的JSON数据绑定到对象上
@ResponseBody
@ResponseBody的作用其实是将java对象转为json格式的数据。
@PathVariable
映射 URL 绑定的占位符
public User getUser(@PathVariable("name") String name){
return userService.selectUser(name);
}@RequestParam
如果变量名称和参数名称不同,可以使用 name 属性配置 @RequestParam 名称
@PostMapping("/api/foos")
@ResponseBody
public String addFoo(@RequestParam(name = "id") String fooId, @RequestParam String name) {
return "ID: " + fooId + " Name: " + name;
}@RequestHeader
从HTTP请求头中获取特定的信息
不常用
@Required
@Qualifier
与数据库连接
jpa
pom依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>3.4.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.6.11.Final</version> <!-- 根据需要调整版本 -->
</dependency>yml文件配置
spring:
application:
name: boot01
datasource:
url: jdbc:mysql://localhost:3306/c1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
# 更新或者创建数据表结构
ddl-auto: update
# 控制台显示SQL
show-sql: true创建实体类
@Entity
@Data
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "user")
public class User {
@Id
private Long id;
@Column(name = "name")
private String name;
@Column(name = "password")
private String password;
}创建Repository类
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
}这个类中内置了一些数据库查询方法,若要自定义:@Query(value=” 这里就是查询语句”)
Mybatis
pom依赖
<!-- Spring Boot MyBatis Starter -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.3</version> <!-- 注意版本 -->
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.8</version>
</dependency>yml配置
spring:
application:
name: boot01
datasource:
url: jdbc:mysql://localhost:3306/c1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
mybatis:
# 配置XML映射文件中指定的实体类别名路径
type-aliases-package: com.origin.dp.entity
# 配置MyBatis的xml配置文件路径
mapper-locations: classpath:mapper/*.xml
# 开启驼峰uName自动映射到u_name
map-underscore-to-camel-case: trueMapper文件
@Mapper
public interface UserMapper {
User getUserById(Long id);
}<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.origin.dp.dao.UserMapper">
<select id="getUserById" resultType="com.origin.dp.entity.User">
select * from user where id = #{id}
</select>
</mapper>数据唯一id
自增id
自增ID(Auto-increment ID)是一种在数据库中常用的主键生成方法,通常用于唯一标识数据库表中的每一行数据
优点
- 唯一性:自增ID保证了每个表中的行都有唯一的标识符,避免了重复数据的问题。
- 简单性:自增ID是一种简单且直观的主键生成方法,易于实现和维护。
- 性能:自增ID可以提高数据库的性能,因为数据库引擎会自动管理并优化自增ID的索引,使数据检索更快速。
- 插入效率:自增ID的顺序插入可以减少数据页的分裂,提高插入效率。
- 隐私性:自增ID不透露关于数据的任何信息,可以保护数据的隐私性。
缺点
- 可预测性:自增ID是连续的数字序列,可能暴露了数据库中数据的规律性,存在安全风险。
- 分布式环境下的问题:在分布式系统中,自增ID的生成可能存在冲突和同步问题,需要额外的处理来确保唯一性。
- 删除数据后的空洞:当删除表中的数据时,可能会留下空洞,导致ID不再是连续的。
- 数据迁移问题:在数据迁移或合并时,可能需要额外考虑自增ID的处理,避免冲突或重复。
- 只适合单机数据库,不能用于分库分表的情况,会产生重复id。
UUID
UUID(Universally Unique Identifier)是一种用于标识信息的唯一标识符,拥有随机、无序,具有非常好的全局唯一性
优点
- 全局唯一性:UUID是全局唯一的标识符,几乎可以保证在不同系统和数据库中生成的UUID都是唯一的。
- 分布式系统支持:在分布式系统中,UUID可以在不同节点上生成唯一的标识符,避免了冲突。
- 随机性:UUID是基于时间和随机数生成的,不易被猜测,提高了安全性。
- 不依赖中心化机制:生成UUID不需要中心化的机制,每个节点都可以独立生成唯一的标识符。
- 无序性:UUID是无序的,不会暴露数据之间的关系,保护了数据的隐私性。
缺点
- 长度:UUID相对于自增ID来说比较长(128位),在存储和索引时占用的空间较大。
- 可读性:UUID是一串十六进制数字和字符,不如自增ID那样直观和易读。
- 性能:生成UUID的算法相对复杂,可能会影响性能,尤其在高并发环境下。
- 不适用于某些场景:在某些情况下,需要连续递增的ID,UUID并不适合。
- 数据库索引问题:由于UUID的无序性,可能会导致索引效率下降,需要额外的处理来优化索引。
雪花ID
有这样一种说法,自然界中并不存在两片完全一样的雪花(世界上没有两片相同的树叶),每一片雪花都拥有自己漂亮独特的形状且是独一无二。
雪花算法也表示生成的 ID 如雪花般独一无二,是一种用于生成分布式系统中唯一ID的算法,由Twitter开发。它的核心思想是将一个64位的ID分成不同的部分,每部分表示不同的信息,例如时间戳、机器ID和序列号。
雪花算法满足唯一性和有序性,避免了分布式系统环境下的ID冲突;并且生成ID的过程中无需依赖数据库等外部系统,减少了系统复杂性
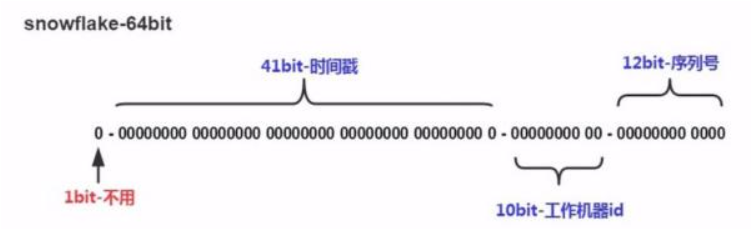
1)第一位 占用1bit,其值始终是0,没有实际作用(因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0)。
2)时间戳 占用41bit,精确到毫秒,总共可以容纳约69年的时间。
3)工作机器id 占用10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,做多可以容纳1024个节点。
4)序列号 占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
优点
- 全局唯一性:雪花算法生成的ID在分布式系统中保证全局唯一,避免了ID冲突的问题。
- 分布式系统支持:雪花算法适用于分布式系统,每个节点可以独立生成唯一的ID,无需中心化的管理。
- 高性能:雪花算法生成ID的速度较快,适用于高并发的场景。
- 简单:相对于一些复杂的ID生成方案,雪花算法相对简单易懂,易于实现和维护。
- 时间有序:雪花算法生成的ID中包含时间戳,可以保证生成的ID在一定程度上是有序的。
缺点
- 时钟回拨问题:如果系统时钟发生回拨,可能会导致生成的ID重复,需要额外处理时钟同步的问题。
- 依赖机器ID:雪花算法中需要分配机器ID,如果分配不当或者机器ID冲突,可能会导致ID冲突。
- 单点故障:如果分配的机器ID集中在少数几台机器上,这些机器出现故障可能会影响整个系统的ID生成。
- 有序性:虽然时间戳可以保证一定的有序性,但在高并发场景下,可能会出现ID递增速度过快导致性能问题。
- 长度固定:雪花算法生成的ID长度固定,可能会占用较多的存储空间。